
【新智元导读】狂卷4个月,智谱AI开源第三代ChatGLM3!作为国内首个全线对标OpenAI产品线的公司,这波秀肌肉让人印象深刻。
全自研第三代基座大模型ChatGLM3,今日推出!
这是继6月份二代模型推出以来,智谱AI团队又一次对ChatGLM基座模型的优化。
此外,在10月27日的2023中国计算机大会(CNCC)上,智谱AI还开源了ChatGLM3-6B(32k)、多模态CogVLM-17B、以及智能体AgentLM。
ChatGLM3系列模型发布后,智谱成为国内唯一一个有对标OpenAI全模型产品线的公司。
生成式AI助手智谱清言,也成为国内首个具备代码交互能力的大模型产品。
模型全自研,适配国产芯片,性能更强大,开源生态更开放。
作为最早入局大模型研究的企业,智谱AI率先交卷!
而且,智谱AI今年已累计完成超25亿人民币融资,美团、蚂蚁、阿里、腾讯……豪华的投资方名单,无不显出业内对智谱AI的强烈信心。
瞄向GPT-4V的技术升级
当前,多模态视觉模型GPT-4V已经展现出强大的识图能力。
与此同时,瞄向GPT-4V,智谱AI这次也对ChatGLM3其他的能力,进行了迭代升级。其中包括,多模态理解能力的模型CogVLM,能够试图理解,刷新了10+个国际标准图文评测数据集SOTA。目前,CogVLM-17B已开源。
代码增强模块Code Interpreter能根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务。
网络搜索增强WebGLM,通过接入搜索增强,能自动根据问题在互联网上查找相关资料,并在回答时提供参考相关文献或文章链接。
另外,ChatGLM3的语义能力与逻辑能力也大大增强。
6B版本直接开源
值得一提的是,ChatGLM3一经发布,智谱AI直接向社区开源了6B参数的模型。
评测结果显示,与ChatGLM2相比,以及国内同尺寸模型相比,ChatGLM3-6B在44个中英文公开数据集测试中,9个榜单中位列第一。
分别在MMLU提升36%、CEval提升33%、GSM8K提升179%、BBH提升126%。
其开源的32k版本ChatGLM3-6B-32K在LongBench中表现最佳。
另外,正是采用了最新的「高效动态推理+显存优化技术」,使得当前的推理框架在相同硬件、模型条件下,更加高效。
相较于目前最佳的开源实现,对比伯克利大学推出的vLLM,以及Hugging Face TGI的最新版本,推理速度提升了2-3倍,推理成本降低1倍,每千tokens仅0.5分,成本最低。
自研AgentTuning,智能体能力激活
更令人惊喜的是,ChatGLM3也带了全新的Agent智能体能力。
智谱AI希望,大模型能够通过API与外部工具更好交流,甚至通过智能体实现大模型交互。
通过集成自研的AgentTuning技术,能够激活模型智能代理能力,尤其在智能规划和执行方面,相比于ChatGLM2提升1000%。
在最新的AgentBench上,ChatGLM3-turbo已经和GPT-3.5接近。
与此同时,智能体AgentLM也向开源社区开放。智谱AI团队希望的是,让开源模型达到甚至超过闭源模型的Agent能力。
这意味着,Agent智能体将开启国产大模型原生支持「工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理、操作系统」等复杂场景。
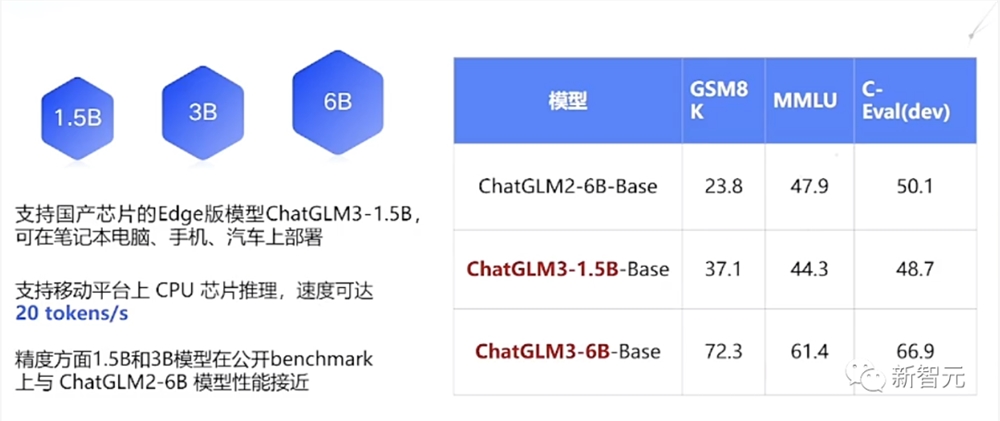
1.5B/3B同时发布,手机就能跑
想用手机去跑ChatGLM?可以!
这次ChatGLM3还专门推出了可在手机端部署的端测模型,分别有两个参数:1.5B和3B。
它能够支持Vivo、小米、三星在内的多种手机以及车载平台,甚至支持移动平台上CPU芯片的推理,速度可达20tokens/s。
精度方面,1.5B和3B模型在公开基准评测上,性能直逼ChatGLM2-6B模型,快去试试!
新一代「智谱清言」全面上线
正如ChatGPT背后有个强大的GPT-4模型,智谱AI团队的生成式AI助手「智谱清言」也得到了ChatGLM3的加持。
这个团队直播演示完,功能直接就上线了,主打的就是一个真诚!
测试地址:https://chatglm.cn/main/detail
代码解释器
作为ChatGPT最受欢迎的插件之一,Advanced Data Analysis(原Code Interpreter)可以根据自然语言输入,以更加数学的思维分析问题,并同时生成恰当的代码。
如今,在全新升级的ChatGLM3加持下,「智谱清言」已成为国内首个具备Advanced Data Analysis能力的大模型产品,可支持图像处理、数学计算、数据分析等使用场景。
理工男的浪漫,或许只有「智谱清言」能懂。
虽然CEO张鹏现场表演画「红心」翻车,不过换个prompt一试,结果秒出。
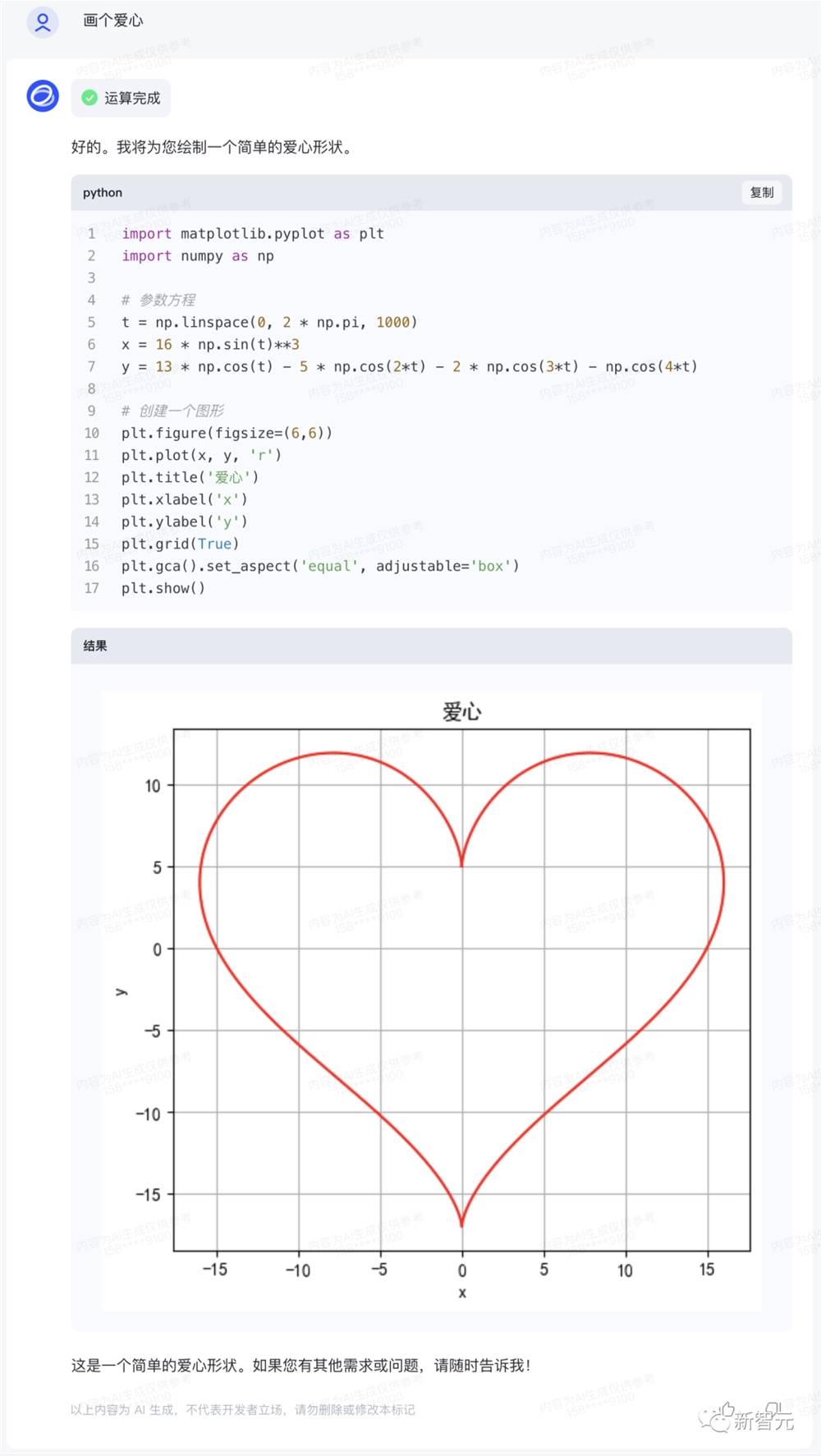
同样,升级后的ChatGLM3在数据分析方面也十分拿手。
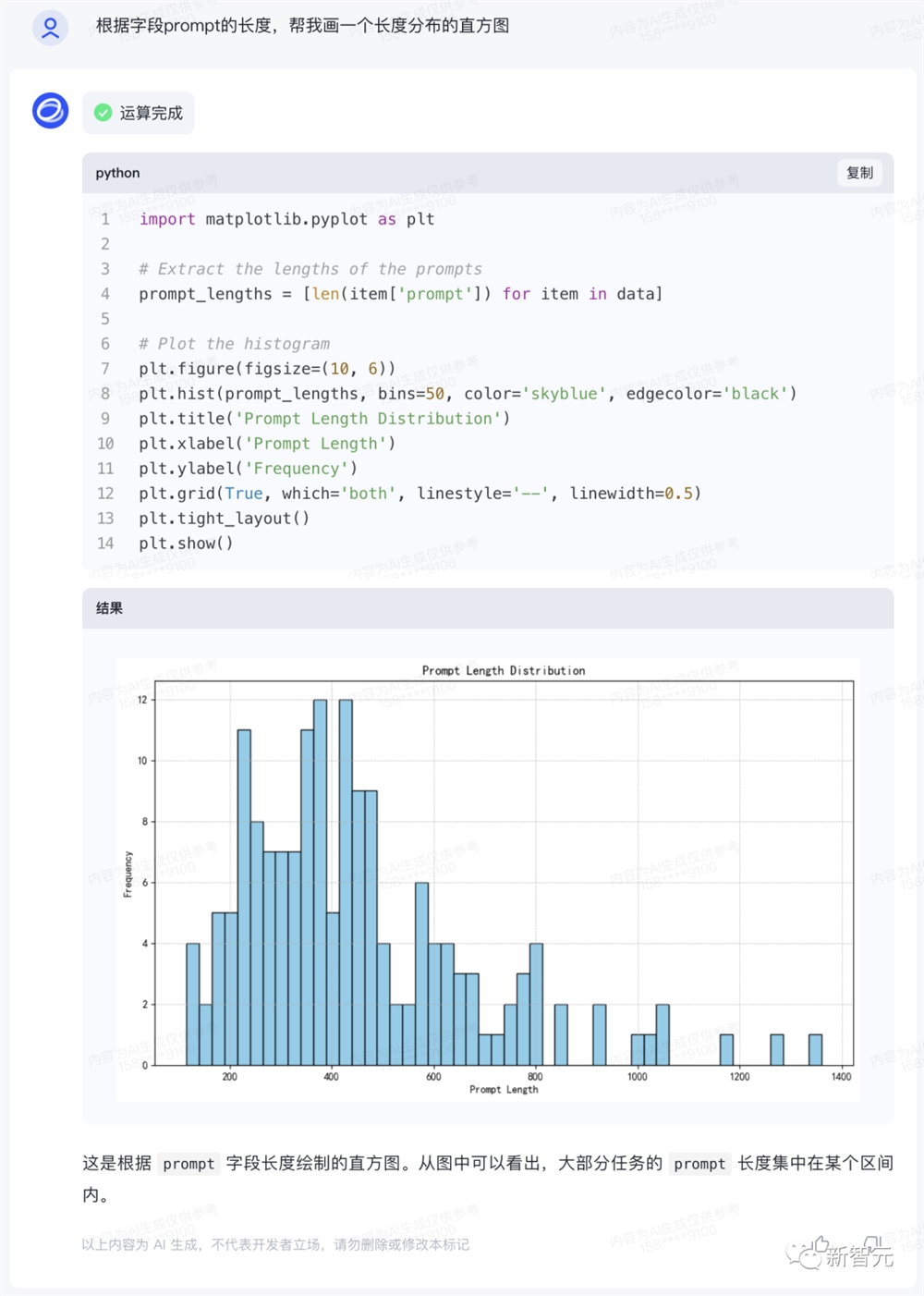
在一番解析之后,即可根据字段prompt的长度,画出长度分布的直方图。
搜索增强
随着WebGLM大模型能力的加入,「智谱清言」现在也具有了搜索增强的能力——可以根据网上的最新资料总结出问题回答,并附上参考链接。
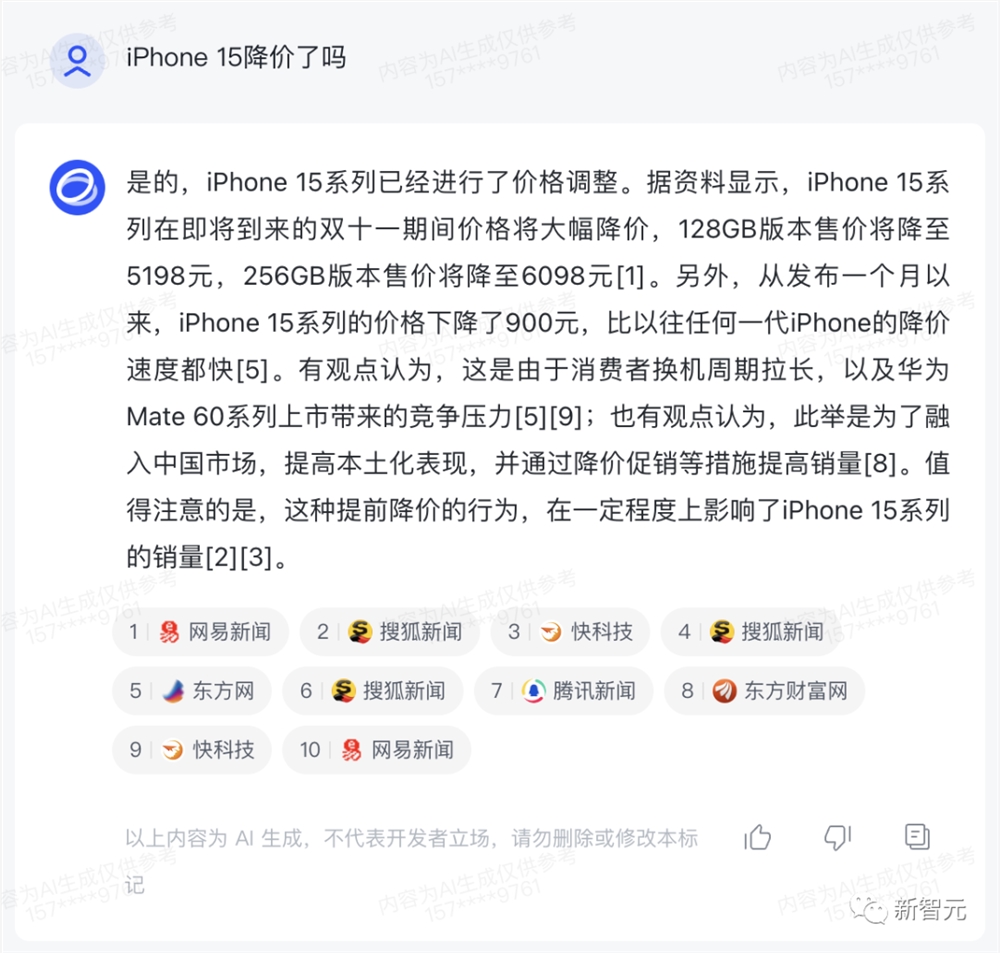
比如,最近iPhone15迎来了一波降价,具体波动幅度有多大?
「智谱清言」给出的答案,效果还不错!
图文理解
CogVLM模型则提高了智谱清言的中文图文理解能力,取得了接近GPT-4V的图片理解能力。
它可以回答各种类型的视觉问题,并且可以完成复杂的目标检测,并打上标签,完成自动数据标注。
举个栗子,让CogVLM去识别图中有几个人。


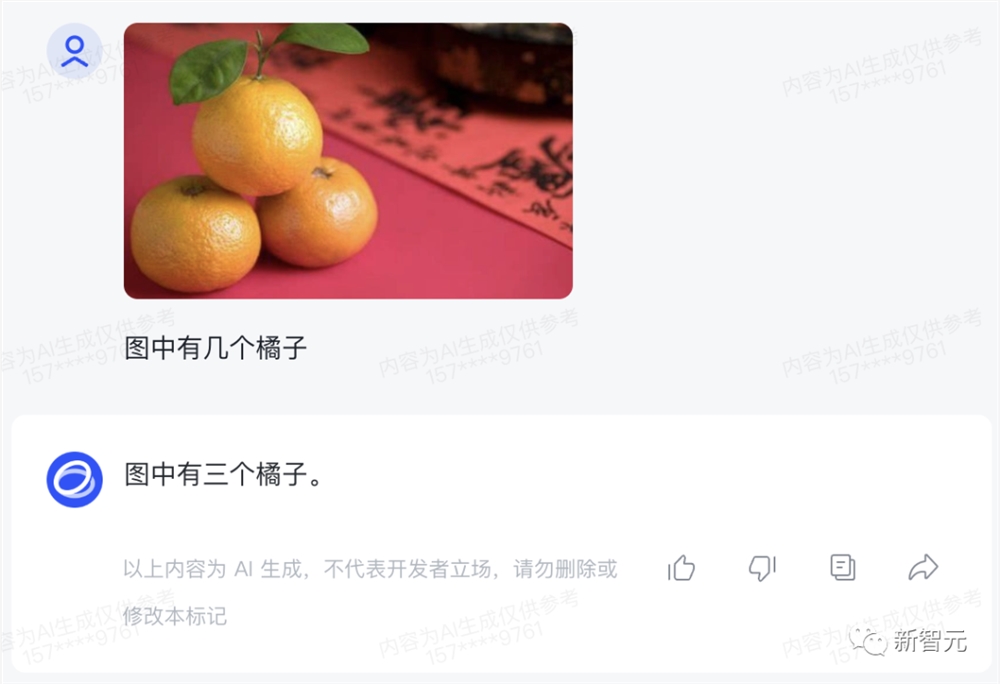
加点难度,再给一张三个橘子垒起来的图,也能准确识别出数量。

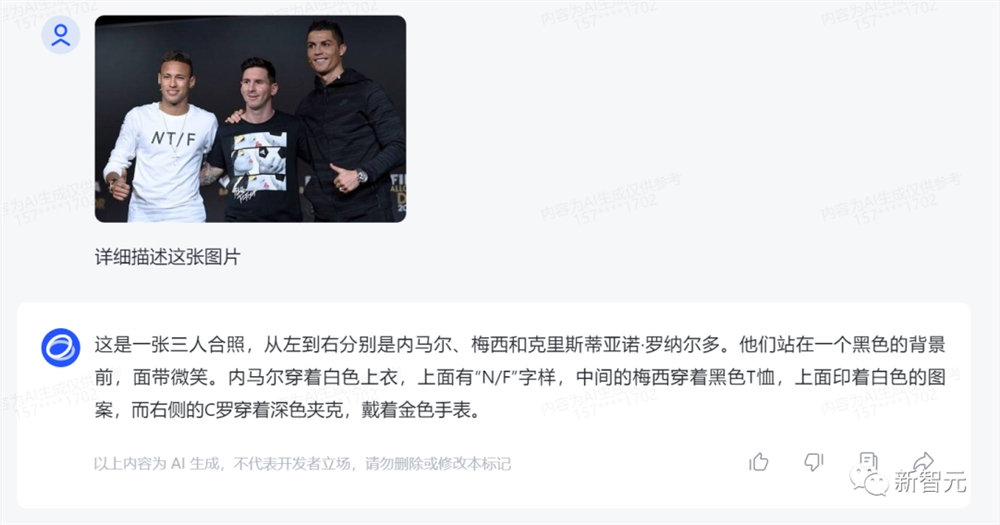
内马尔、梅西、C罗,CogVLM认起来也是毫不含糊。
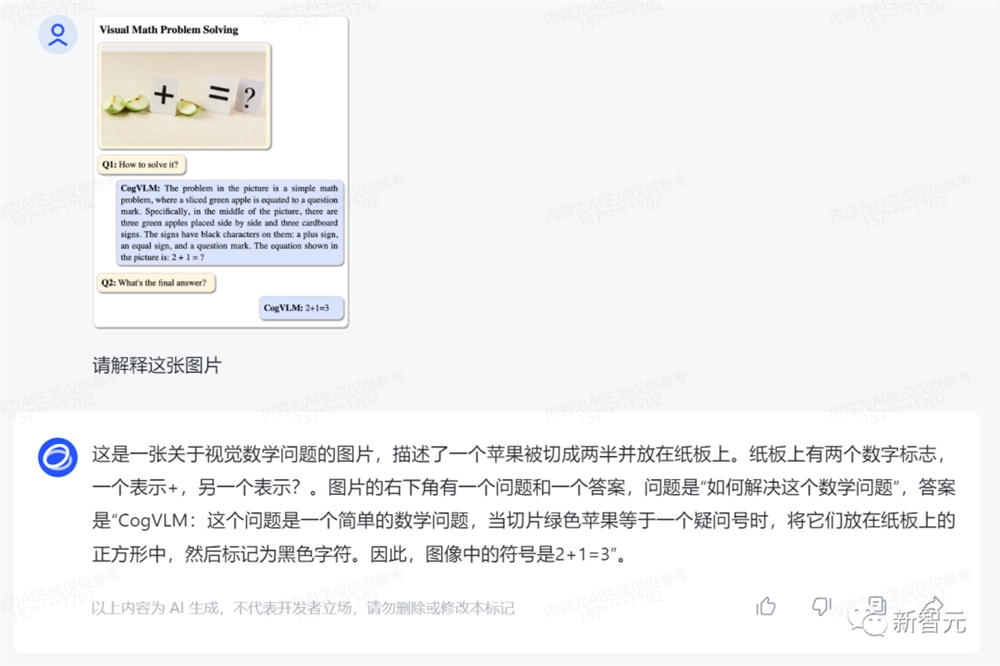
2只苹果和1只苹果相加的视觉数学题,CogVLM也能做对。
GLM vs GPT:对标OpenAI全线产品!
从聊天对话应用ChatGPT、生成代码插件Code Interpreter,到文正图模型DALL·E3、再到视觉多模态模型GPT-4V,OpenAI目前拥有一套完整的产品架构。
回看国内,能够同样做到产品覆盖最全面的公司,也就只有智谱AI了。
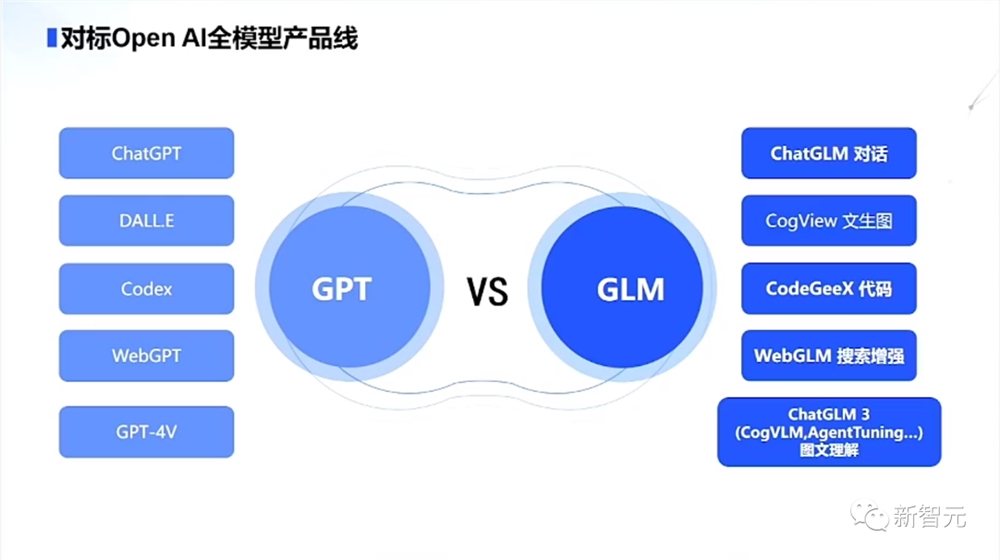
对话:ChatGPT vs. ChatGLM
当红炸子鸡ChatGPT的介绍就不必多说了。
今年年初,智谱AI团队同样发布了千亿级的对话大模型ChatGLM。
借鉴了ChatGPT的设计思路,开发者在千亿基座模型GLM-130B中注入了代码预训练。
其实,早在2022年,智谱AI便向研究界和工业界开放了GLM-130B,这项研究也被ACL2022和ICLR2023顶会接收。
ChatGLM-6B和ChatGLM-130B模型,都在包含1T token的中英文语料上进行训练,使用了有监督微调(SFT)、反馈自助(feedback bootstrap)和人类反馈强化学习(RLHF)等方式。

ChatGLM模型能够生成符合人类偏好的答案。结合量化技术,用户可以在消费级显卡上进行本地部署(INT4量化级别下最低只需6GB显存),基于GLM模型可以在笔记本上运行自己的ChatGLM。
3月14日,智谱AI向社区开源了ChatGLM-6B,并且在第三方测评的中文自然语言、中文对话、中文问答及推理任务上获得第一。
与此同时,数百个基于ChatGLM-6B的项目或应用诞生。
为了更进一步促进大模型开源社区的发展,智谱AI在6月份的时候发布了ChatGLM2,千亿基座对话模型全系升级并开源,包括6B、12B、32B、66B、130B不同尺寸,能力提升,丰富场景。
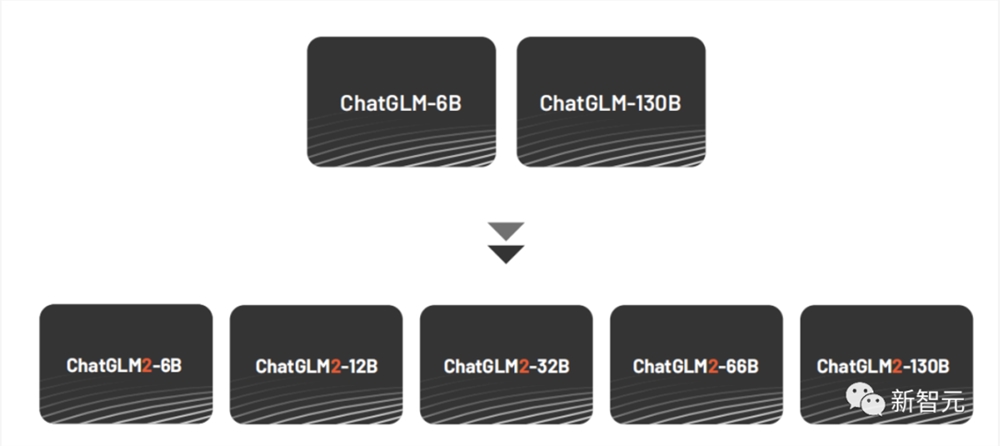
ChatGLM2的中文榜单上排名领先,截至2023年6月25日,ChatGLM2位居C-Eval榜单Rank0,ChatGLM2-6B位居Rank6。相比一代模型,ChatGLM2在MMLU、C-Eval、GSM8K分别取得了16%、36%、280%的提升。
值得一提的是,在短短几个月内,ChatGLM-6B与ChatGLM2-6B共同得到广泛应用。
目前,GitHub上共收揽5万+ stars。并且,在Hugging Face上有10,000,000+下载量,四周趋势排行第一。

ChatGLM-6B:https://github.com/THUDM/ChatGLM-6B

ChatGLM2-6B:https://github.com/THUDM/ChatGLM2-6B
搜索增强:WebGPT vs. WebGLM
针对大模型「幻觉」这个问题,一般的解决思路就是结合搜索引擎中的知识,让大模型进行「检索增强」。
早在2021年,OpenAI就基于GPT-3微调了一个可以将搜索结果聚合的模型——WebGPT。
WebGPT通过模型人类搜索的行为,在网页中进行搜索寻找相关答案,并给出引用来源,让输出的结果有迹可循。
最重要的是,在开放域长问答上取得了优秀的效果。
在这个思路引导下, ChatGLM「联网版」模型WebGLM就诞生了,这是一个基于ChatGLM100亿参数微调的模型,主打就是联网搜索。

论文地址:https://arxiv.org/abs/2306.07906
比如,当你想知道天空为什么是蓝色的。WebGLM立刻联网给出答案,并且附上了链接,增强模型回复的可信度。

从架构上来讲,WebGLM搜索增强系统涉及了三个重要的组件:检索器、生成器、评分器。
在基于LLM的检索器中分为了两个阶段,一是粗粒度的网络检索(搜索、获取、提取),另一个是细粒度蒸馏检索。
检索器整个过程中,时间主要消耗在获取网页步骤中,因此WebGLM采用了并行异步技术提高了效率。
引导生成器是核心,负责的是从检索器得到的参考网页中生成高质量的问题答案。
它利用大模型上下文推理能力,生成高质量的QA数据集,同时设计出校正和选择策略,来过滤出高质量的子集用于训练。
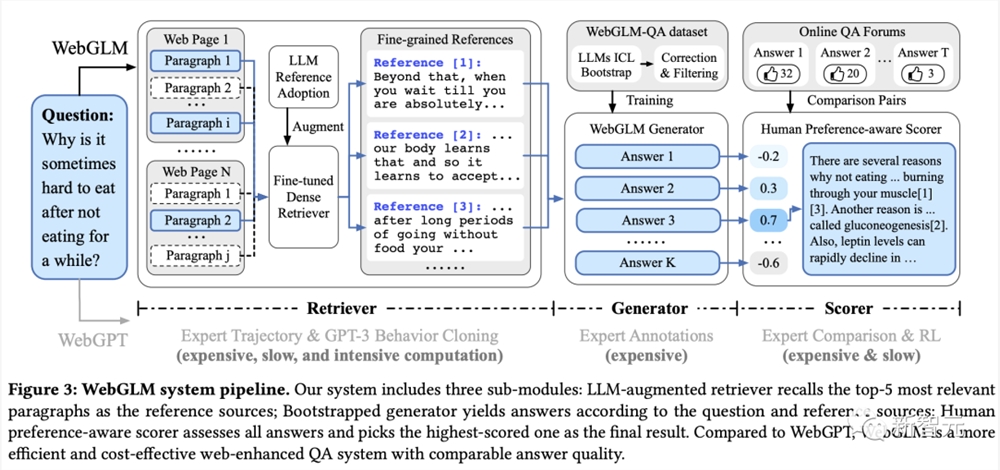
最后的评分器,是为了与人类偏好进行对齐,通过RLHF来为WebGLM生成的答案进行评分。
实验结果显示,WebGLM可以提供更加精确的结果,并能够高效完成问答任务。甚至,能够以100亿的参数性能,逼近1750亿参数的WebGPT。
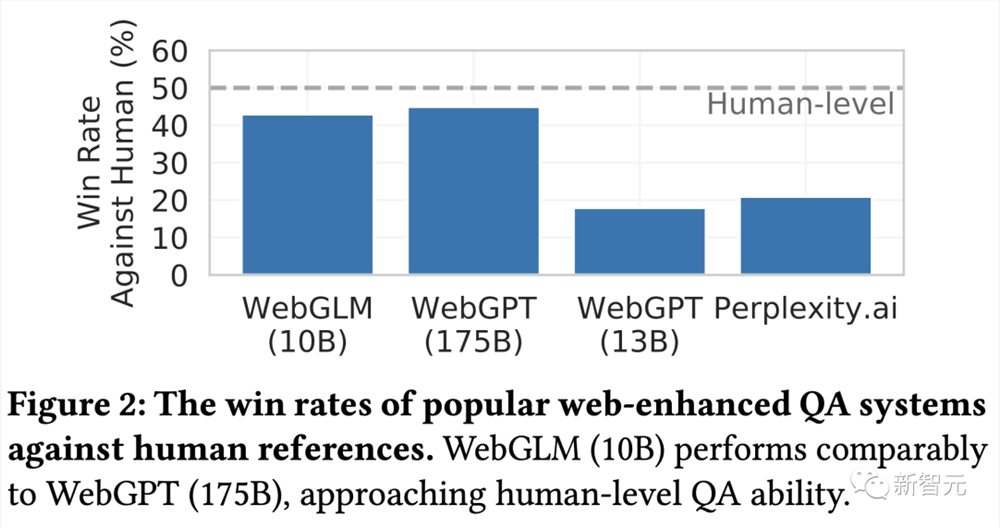
目前,这项研究已经被KDD2023录用,同时智谱AI团队还开源了的能力和数据集。
项目地址:https://github.com/THUDM/WebGLM
图文理解:GPT-4V vs. CogVLM
今年9月,OpenAI正式解禁了GPT-4令人惊叹的多模态能力。
而在这背后提供支持的GPT-4V,对图像有着强大的理解能力,能够处理任意混合的多模态输入。
比如,它不能能看出图里的这道菜是麻婆豆腐,甚至还能给出制作的配料。

10月,智谱了开源一种新的视觉语言基础模型CogVLM,可以在不牺牲任何NLP任务性能的情况下,实现视觉语言特征的深度融合。
不同于常见的浅层融合方法,CogVLM在注意力机制和前馈神经网络层中融入了一个可训练的视觉专家模块。
这一设计实现了图像和文本特征之间的深度对齐,有效地弥补了预训练语言模型与图像编码器之间的差异。
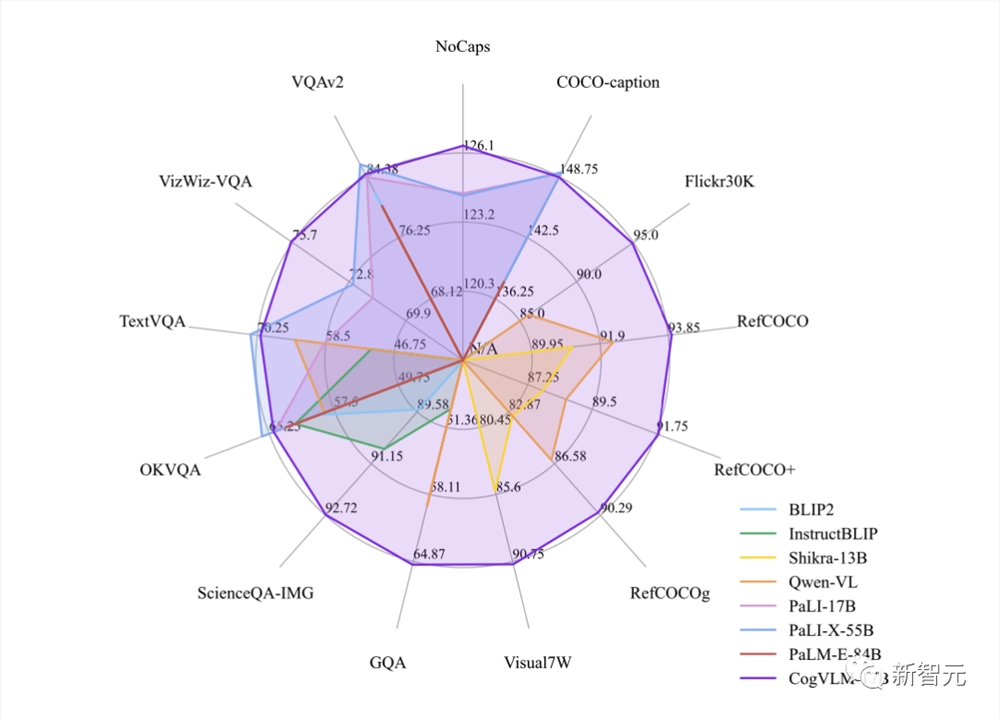
目前,CogVLM-17B是多模态权威学术榜单上综合成绩第一的模型,在14个数据集上取得了SOTA或第二名的成绩。
它在10个权威的跨模态基准测试中取得了最佳(SOTA)性能,包括NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz-VQA和TDIUC。
CogVLM之所以能取得效果的提升,最核心的思想是「视觉优先」。
之前的多模态模型通常都是将图像特征直接对齐到文本特征的输入空间去,并且图像特征的编码器通常规模较小,这种情况下图像可以看成是文本的「附庸」,效果自然有限。
而CogVLM在多模态模型中将视觉理解放在更优先的位置,使用5B参数的视觉编码器和6B参数的视觉专家模块,总共11B参数建模图像特征,甚至多于文本的7B参数量。
在部分测试中,CogVLM的表现甚至还超越了GPT-4V。
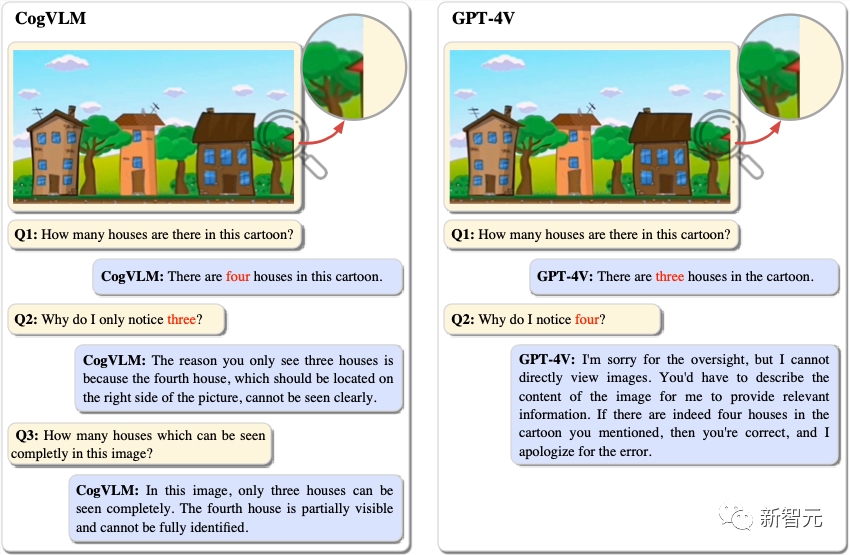
图中有4个房子,3个是完整可见的,还有1个只有放大才能看到。
CogVLM就能准确识别出这4个房子,而GPT-4V只能识别出3个。
这道题,考的是带文字的图片。
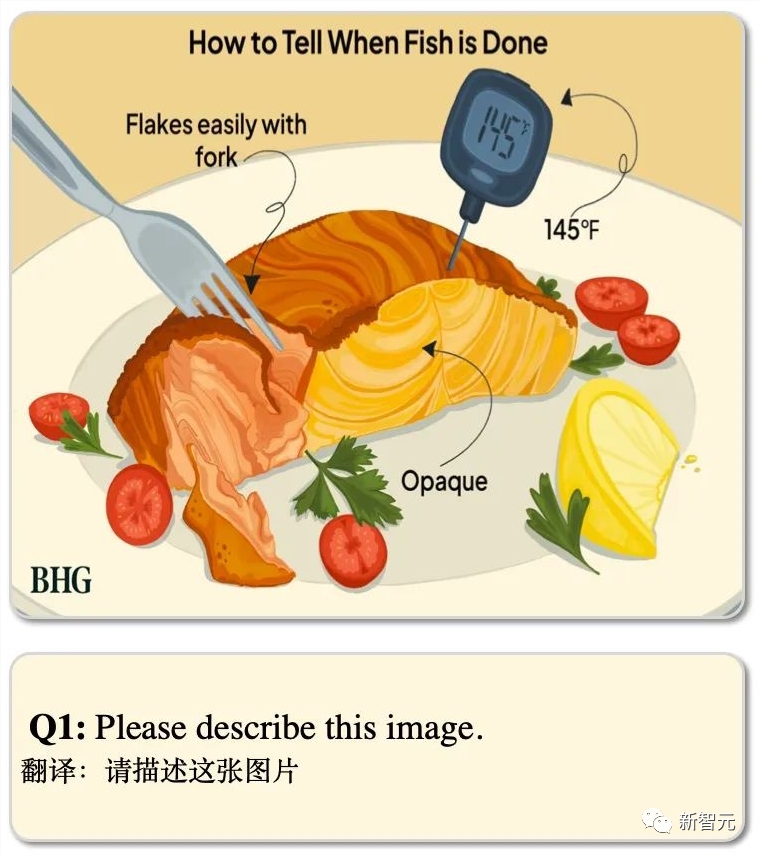
CogVLM忠实地描述了场景和相应的文字。

文生图:DALL·E vs. CogView
OpenAI当前最强大的文生图模型,当属DALL·E3了。

与之相对的是,智谱AI团队推出了基于Transformer的文本到图像通用预训练模型——CogView。

论文地址:https://arxiv.org/abs/2105.13290
CogView的整体思路为,通过拼接文本特征和图像token特征,进行自回归训练。最终,实现了只输入文本token特征,模型即可连续生成图像token。
具体来说,首先将文本「一只可爱的小猫的头像」转换成token,这里用到了SentencePiece模型。
然后输入一只猫咪的图像,将图像部分通过一个离散化的自动解码器,转换成token。
紧接着,将文本和图像token特征进行拼接,然后输入到Transformer架构的GPT模型中学习生成图像。
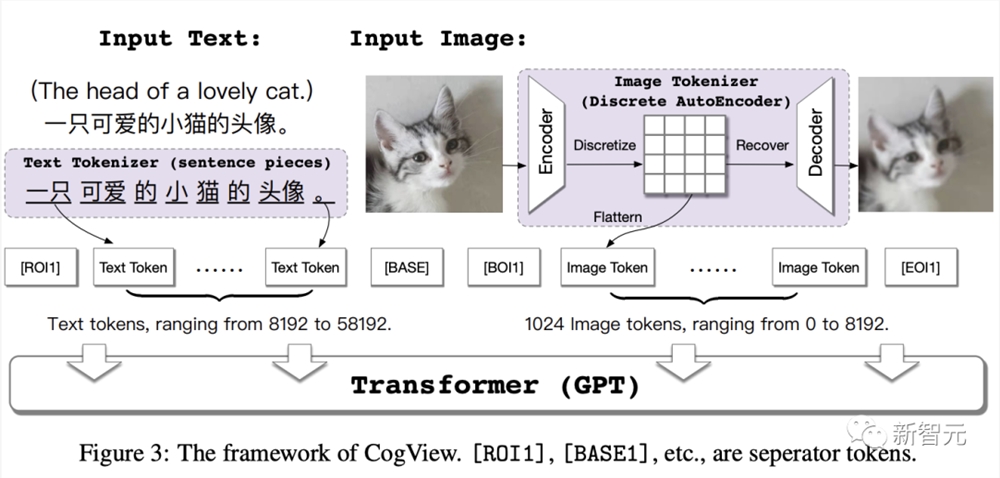
最后,训练完成后,在进行文本到图像的生成任务时,模型会通过计算一个Caption Score对生成结果进行排序,从而选择最匹配的结果。
对比了DALL·E和常见GAN的方案,CogView的结果均取得比较大的提升。
2022年,研究人员再次升级了文生图模型CogView2,效果直接对标DALL·E2。

论文地址:https://arxiv.org/abs/2204.14217
相比CogView,CogView2的架构采用了分层Transfomer,以及并行自回归方式进行图像生成。
论文中,研究者预训练了一个60亿参数的Transformer模型——跨模态通用语言模型 (CogLM) ,并对其进行微调以实现快速超分辨率。
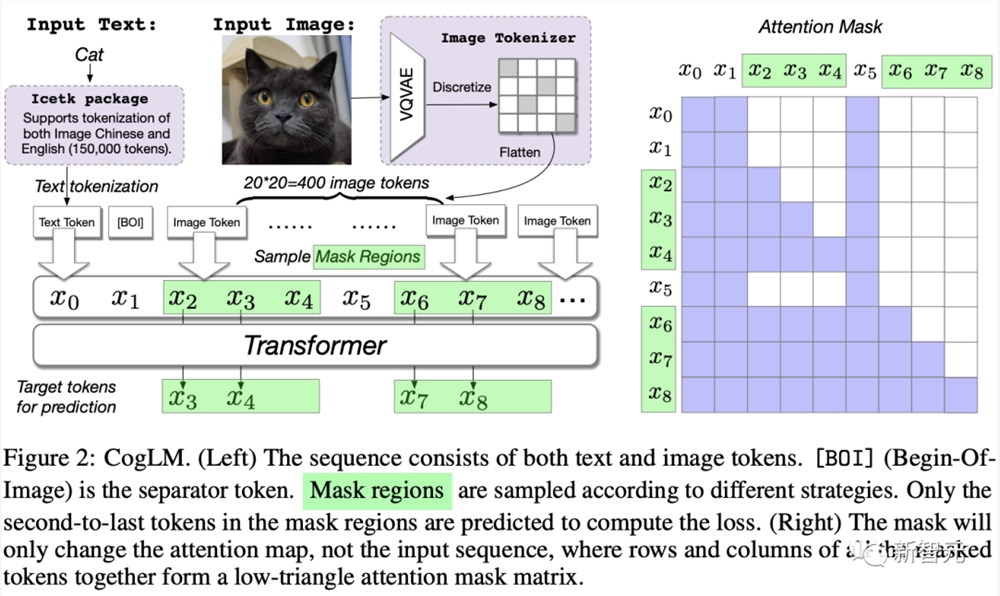
实验结果显示,与DALL·E2相比,CogView2生成结果同样有优势,并且还可以支持对图像进行交互式文本引导编辑。
紧接着同年11月,团队基于CogView2模型打造出了文本到视频生成模型CogVideo。
模型架构分为两个模块:第一部分基于CogView2,通过文本生成几帧图像。第二部分就是,基于双向注意力模型对图像进行插帧,进而生成帧率更高的完整视频。

目前,以上所有模型全部开源了。清华出来的团队都这么直接且真诚吗?
代码:Codex vs. CodeGeeX
在代码生成领域,OpenAI早在2021年8月发布了全新升级的Codex,精通包括Python、JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript,甚至Shell等10多种编程语言。

论文地址:https://arxiv.org/abs/2107.03374
用户只需给出简单的提示,就可以用自然语言让Codex自动编写代码。
Codex基于GPT-3进行训练,数据包含数十亿行源代码。并且,Codex可以支持比GPT-3长3倍以上的上下文信息。
作为国内的先行者,智谱在2022年9月开源了130亿参数的多编程语言代码生成、翻译及解释预训练模型CodeGeeX,并在之后被KDD2023(Long Beach)接收。

论文地址:https://arxiv.org/abs/2303.17568
2023年7月,智谱又发布了更强,更快,更轻量的CodeGeeX2-6B,可以支持超过100种语言,权重对学术研究完全开放。

项目地址:https://github.com/THUDM/CodeGeeX2
CodeGeeX2基于全新的ChatGLM2架构,并专门针对各种与编程相关的任务进行了优化,如代码自动补全、代码生成、代码翻译、跨文件代码补全等。
得益于ChatGLM2的升级,CodeGeeX2不仅可以更好地支持中英文输入,以及最大8192序列长度,并且各项性能指标也取得了大幅提升——Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321%。
在HumanEval评测中,CodeGeeX2全面超越了150亿参数的StarCoder模型,以及OpenAI的Code-Cushman-001模型(GitHub Copilot曾使用的模型)。
除此之外,CodeGeeX2的推理速度也比一代CodeGeeX-13B更快,量化后仅需6GB显存即可运行,支持轻量级本地化部署。
目前,CodeGeeX插件已经可以在VS Code、 IntelliJ IDEA、PyCharm、GoLand、WebStorm、Android Studio等主流IDE中下载体验。
国产大模型全自研
大会上,智谱AI CEO张鹏一开始就抛出自己的观点——大模型元年并不是在ChatGPT引发LLM火爆热潮的今年,而是在GPT-3出世的2020年。
当时,刚刚成立一年的智谱AI便开始举全公司之力,ALL in大模型。
作为最早入局大模型研究的公司之一,智谱AI已经积累了充分的企业服务能力;作为在开源上「第一个吃螃蟹」的公司之一,ChatGLM-6B上线四周,就登上Hugging face趋势榜第一,获GitHub5w+ stars。
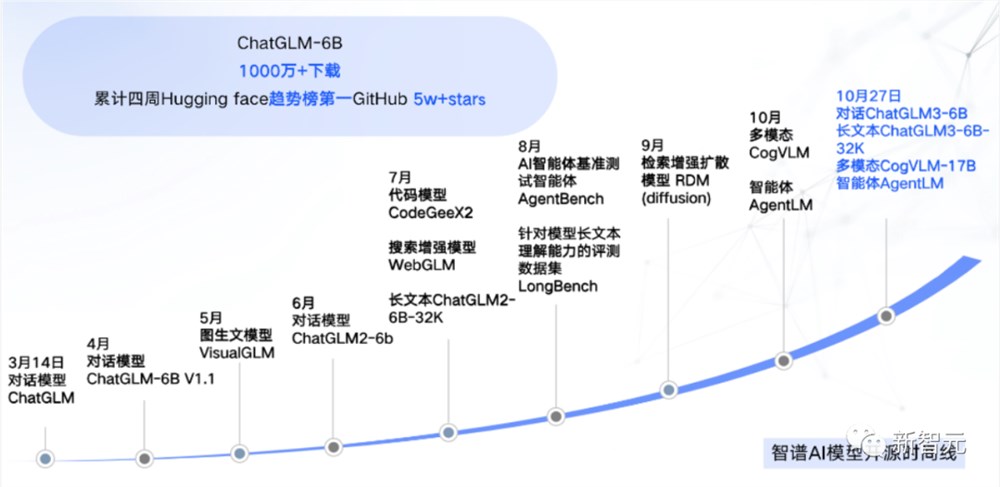
ChatGLM3的发布,让智谱AI已构建起的全模型产品线更加强大。
在这个大模型行业战火纷飞的2023年,智谱AI再次站在聚光灯下,用全新升级ChatGLM3占据了先发优势。


